The
previous installment was titled "(Almost) Difference Lists" because there was one operation that we could (technically) do on a Prolog difference list that we can't do on the difference lists described in the previous section. If a Prolog difference list is
known to be nonempty, it's possible to match against the front of the list. Noone ever does this that I can tell, because if the Prolog difference list
is empty, this will mess up all the invariants of the difference list. Still, however, it's there.
We will modify our language to allow
pattern matching on linear functions, which is like pattern matching on a difference list but better, because we can safely handle emptiness. The immediate application of this is that we have a list-like structure that allows constant time affix-to-the-end and remove-from-the-beginning operations: a queue! Due to the similarity with difference lists, I'll call this curious new beast a
difference queue. This is all rather straightforward, except for the dicussion of coverage checking, which involves a well-understood analysis called
subordination. But we'll cross that bridge when we come to it.
A pattern matching aside. Pattern matching against functions? It's certainly the case that in ML we can't pattern match against functions, but as we've already discussed towards the end of the
intro to Levy#, the linear function space is not a
computational function space like the one in ML, it's a
representational function space like the one in LF/Twelf, a distinction that comes from Dan Licata, Bob Harper, and Noam Zeilberger [
1,
2]. And we pattern match against representational functions all the time in LF/Twelf. Taking this kind of pattern matching from the logic programming world of Twelf into the functional programming world is famously tricky (leading to proposals like
Beluga,
Delphin, (sort of)
Abella, and the aforementioned efforts of Licata et al.), but the trickiness is always from attempts to open up a (representational) function, do something computational on the inside, and then put it back together. We're not going to need to do anything like that, luckily for us.
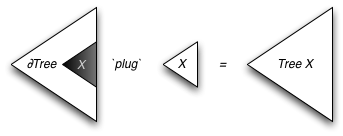
Difference queues
We're going to implement difference queues as values of type
q -o q, where
q is an interesting type: because definitions are inductive, the type
q actually has no inhabitants.
data QCons: int -o q -o q ;;
An alternative would be to implement difference queues using the difference lists
list -o list from the previous installment, which would work fine too.
We'll also have an option type, since de-queueing might return nothing if the queue is empty, as well as a "valof" equivalent operation to force the queue from something that may or may not be a queue. This
getq option will raise a non-exhaustive match warning during coverage checking, since it can obviously raise a runtime error.
data None: option
| Some: int -o (q -o q) -o option ;;
val getq = thunk fun opt: option ->
let (Some _ q) be opt in return q ;;
The operations to make a new queue and to push an item onto the end of the queue use the functionality that we've already presented:
val new = thunk return [x:q] x ;;
val push = thunk
fun i: int ->
fun queue: (q -o q) ->
return [x:q] queue (QCons i x) ;;
The new functionality comes from the
pop function, which matches against the front of the list. An empty queue is represented by the identity function.
val pop = thunk fun queue: (q -o q) ->
match queue with
| [x:q] x -> return None
| [x:q] QCons i (queue' x) -> return Some i queue' ;;
Lets take a closer look at the second pattern,
[x:q] QCons i (queue' x). The
QCons constructor has two arguments, and because the linear variable
x occurs exactly once, it has to appear in one of the two arguments. This pattern is intended to match the case where the linear variable
x appears in the second argument of the constructor (read: inside of the the
q part, not inside of the
int part), and the pattern binds a linear function
queue' that has type
q -o q.
You can see how these difference queues are used in
linearqueue.levy.
Another pattern matching aside. The above-mentioned patterns (and, in fact, all accepted patterns in this current extension of Levy#) actually come from the set of Linear LF terms that are in what is known as the
pattern fragment (appropriately enough). The pattern fragment was first identified by Dale Miller as a way of carving out a set of unification problems on higher-order terms that could 1) always be given unitary and decidable solutions and 2) capture many of the actual unification problems that might arise in λProlog [
3]. Anders Schack-Nielsen and Carsten Schürmann later generalized this to Linear LF [
4], which as I've described is the language that we're essentially using to describe our data.
Coverage checking with subordination
In the previous section we saw that the two patterns
[x:q] x and
[x:q] QCons i (queue' x) were used to match against a value of type
q -o q, and the coverage checker in Levy# accepted those two patterns as providing a complete case analysis of values of this type. But the constructor
QCons has two arguments; why was the coverage checker satisfied with a case analysis that only considered the linear variable occurring in the second argument?
To understand this, consider the pattern
[x:q] x and
[x:q] QCons (di x) queue', where the linear variable does occur in the first argument. This pattern binds the variable
di, a linear function value of type
q -o int. But the only inhabitants of type
int are constants, and the
q must go somewhere; where can it go? It can't go anywhere! This effectively means that there are
no closed values of type q -o int, so there's no need to consider what happens if the
q hole appears inside of the first argument to
QCons.
Because of these considerations, Levy# has to calculate what is called the
subordination relation for the declared datatypes. Subordination is an analysis developed for Twelf that figures out what types of terms can appear as subterms of other types of terms. I added a new keyword to Levy# for reporting this subordination information:
Levy> $subord ;;
Subordination for current datatypes:
int <| q
q <| q
int <| option
So
int is subordinate to both
q and
option, and
q is subordinate only to itself. Subordination is intended to be a conservative analysis, so this means that there
might be values of type
int -o q and
int -o option and that there
might be non-identity values of type
q -o q, but that there are
no values of type
q -o option and the only value of type
option -o option is
[x: option] x. Levy# uses the no-overlapping-holes restriction to make subordination analysis more precise; without this restriction, a reasonable subordination analysis would likely declare
q subordinate to
option.
1
Some more examples of subordination interacting with coverage checking can be seen in
linearmatch.levy.
Subordination and identity in case analysis
We use subordination data for one other optimization. The following function is also from
linearmatch.levy; it takes a value of type
int -o list and discards everything until the place where the hole in the list was.
val run = thunk rec run: (int -o list) -> F list is
fun x: (int -o list) ->
match x with
| [hole: int] Cons hole l -> return l
| [hole: int] Cons i (dx hole) -> force run dx ;;
Because Levy# is limited to depth-1 pattern matching, a pattern match should really only say that the hole is
somewhere in a subterm, not that the hole is
exactly at a subterm. This would indicate that the first pattern should really be
[hole: int] Cons (di hole) l, but by subordination analysis, we know that
int is not subordinate to
int and so therefore the only value of type
int -o int is the identity function, so
di = [hole:int] hole and we can beta-reduce
([hole:int] hole) hole to get just
hole.
So subordination is a very helpful analysis for us; it allows us to avoid writing some patterns altogether (patterns that bind variables with types that aren't inhabited) and it lets us simplify other patterns by noticing that for certain types "the hole appears somewhere in this subterm" is exactly the same statement as "this subterm is exactly the hole."
Implementation
In order to efficiently pattern match against the beginning of a list, we need to be able to rapidly tell which sub-part of a data structure the hole can be found in. This wasn't a problem for difference lists and difference queues, since subordination analysis is enough to tell us where the hole will be if it exists, but consider trees defined as follows:
data Leaf: tree
| Node: tree -o tree -o tree ;;
If we match against a value of type
tree -o tree, we need to deal with the possibility that it is the identity function, the possibility that the hole is in the left subtree, and the possibility that the hole is in the right subtree. This means that, if we wish for matching to be a constant-time operation, we also need to be able to
detect whether the hole is in the left or right subtree without doing a search of the whole tree.
This is achieved by adding an extra optional field to the in-memory representation of structures, a number that indicates where the hole is. Jason Reed correctly pointed out in a
comment that for the language extension described in the previous installment, there was actually no real obstacle to having the runtime handle multiple overlapping holes and types like
tree -o (tree -o tree). But due to the way we're modifying the data representation to do matching, the restriction to having at most one hole at a time is now critical: the runtime stores directions to
the hole at every point in the structure.
The memory representation produced by the value code
[hole: tree] Node (Node Leaf Leaf) (Node (Node hole Leaf) Leaf) might look something like this, where I represent the number indicating where the hole is by circling the indicated hole in red:

If the hole is filled, the extra data (the red circles) will still exist, but the part of the runtime that does operations on normal inductively defined datatypes can just ignore the presence of this extra data. (In a full implementation of these ideas, this would likely complicate garbage collection somewhat.)
Case Study: Holey Trees and Zippers
The binary trees discussed before, augmented with integers at the leaves, are the topic of this case study. A famous data structure for functional generic programming is Huet's zipper [
5,
6], which describes inside-out paths through inductive types such as trees. The idea of a zipper is that it allows a programmer to place themselves
inside a tree and move up, left-down, and right-down the tree using only constant-time operations based on pointer manipulation.
The zipper for trees looks like this:
data Top: path
| Left: path -o tree -o path
| Right: tree -o path -o path ;;
In this case study, we will show how to coerce linear functions
tree -o tree into the zipper data structure
path and vice versa.
In order to go from a linear function
tree -o tree to a zipper
path, we use a function that takes two arguments, an "outside"
path and an "inside"
tree -o tree. As we descend into the tree-with-a-hole by pattern matching against the linear function, we tack the subtrees that aren't on the path to the hole onto the outside
path, so that in every recursive call the zipper gets bigger and the linear function gets smaller.
val zip_of_lin = thunk rec enzip: path -> (tree -o tree) -> F path is
fun outside: path ->
fun inside: (tree -o tree) ->
match inside with
| [hole: tree] hole ->
return outside
| [hole: tree] Node (left hole) right ->
force enzip (Left outside right) left
| [hole: tree] Node left (right hole) ->
force enzip (Right left outside) right ;;
Given this function, the obvious implementation of its inverse just does the opposite, shrinking the zipper with every recursive call and tacking the removed data onto the linear function:
val lin_of_zip = thunk rec enlin: path -> (tree -o tree) -> F (tree -o tree) is
fun outside: path ->
fun inside: (tree -o tree) ->
match outside with
| Top ->
return inside
| Left path right ->
force enlin path ([hole: tree] Node (inside hole) right)
| Right left path ->
force enlin path ([hole: tree] Node left (inside hole)) ;;
That's the obvious implementation, where we tack things on to the outside of the linear function. Linear functions have the property, of course, that you can tack things on to the inside or the outside, which gives us the opportunity to consider another way of writing the inverse that looks more traditionally like an induction on the structure of the zipper:
val lin_of_zip' = thunk rec enlin: path -> F (tree -o tree) is
fun path: path ->
match path with
| Top -> return [hole: tree] hole
| Left path right ->
force enlin path to lin in
return [hole: tree] lin (Node hole right)
| Right left path ->
force enlin path to lin in
return [hole: tree] lin (Node left hole) ;;
These functions, and examples of their usage, can be found in
linear-vs-zipper.levy.
Foreshadowing
This installment was written quickly after the first one; I imagine there will be a bigger gap before the third installment, so I'm going to go ahead and say a bit about where I'm going with this, using the case study as motivation.
I wrote three functions:
- lin_of_zip turns zippers into linear functions by case analyzing the zipper and tacking stuff onto the "beginning" our outside of the linear function,
- lin_of_zip' turns zippers into linear functions by inducting over the path and tacking stuff onto the "end" or inside of the linear function, and
- zip_of_lin turns linear functions into zippers by case analyzing the "beginning" or outside of the linear function and tacking stuff on to the zipper.
What about
zip_of_lin', which turns linear functions into zippers by case analyzing the "end" or inside of the linear function? It's easy enough to describe what this function would look like:
# val zip_of_lin' = thunk rec enzip: (tree -o tree) -> F path is
# fun lin: (tree -o tree) ->
# match lin with
# | [hole: tree] hole -> return Top
# | [hole: tree] lin' (Node hole right) ->
# force enzip lin' to path in
# return Left path right
# | [hole: tree] lin' (Node left hole) ->
# force enzip lin' to path in
# return Right left path ;;
Toto, we're not in the pattern fragment anymore, but if we turn the representation of linear functions into
doubly linked lists (or a double-ended-queues implemented as linked lists, perhaps), I believe we can implement these functions without trouble. At that point, we basically don't need the zippers anymore: instead of declaring that
the derivative of a type is the type of its one-hole contexts, we can make the obvious statement that the linear function from a type to itself is the type of one-hole contexts of that type, and we can program accordingly: no new boilerplate datatype declarations needed!
Conclusion
A relatively simple modification of the runtime from the previous installment, a runtime data tag telling us where the hole is, allows us to efficiently pattern match against linear representational functions. This modification makes the use of linear representational functions far more general than just a tool for efficiently implementing a logic programming idiom of difference lists. In fact, I hope the case study gives a convincing case that these holey data structures can come close to capturing many of the idioms of
generic programming, though that argument won't be fully developed until the third installment, where we move beyond patterns that come from the Miller/Schack-Nielsen/Schürmann pattern fragment.
More broadly, we have given a purely logical and declarative type system that can implement algorithms that would generally be characterized as imperative algorithms, not functional algorithms. Is it fair to call the queue representation a "functional data structure"? It is quite literally a data structure that is a function, after all! If it is (and I'm not sure it is), this would seem to challenge at least my personal understanding of what "
functional data structures" and functional algorithms are in the first place.
1 This is true even though there are, in fact, no closed values of type q -o option even if we don't have the no-overlapping-holes restriction (proof left as an exercise for the reader).
[1] Daniel R. Licata, Noam Zeilberger, and Robert Harper, "Focusing on Binding and Computation," LICS 2008.
[2] Daniel R. Licata and Robert Harper, "A Universe of Binding and Computation," ICFP 2009.
[3] Dale Miller, "A Logic Programming Language with Lambda-Abstraction, Function Variables, and Simple Unification," JLC 1(4), 1991.
[4] Anders Schack-Nielsen and Carsten Schürmann, "Pattern Unification for the Lambda Calculus with Linear and Affine Types," LFMTP 2010.
[5] Gúrard Huet, "Function Pearl: The Zipper," JFP 1997.
[6] Wikipedia: Zipper (data structure).
 dvanhorn@λ-calcul.us
dvanhorn@λ-calcul.us Chung-chieh Shan
Chung-chieh Shan