- As a prelude, I introduced the Levy# language, Bauer and Pretnar's implementation of call-by-push-value, a programming formalism that is very persnickety about the difference between value code and computation code, extended with datatypes. I have come to the position, especially after a conversation with Dan Licata, that we should really think of Levy# as an A-normal form intermediate language that is explicit about control: using it allowed me to avoid certain red herrings that would have arisen in an ML-like syntax, but you'd really want the ML-like language to actually program in.
- In Part 1, I showed how representational linear functions could capture a logic programming idiom, difference lists. Difference lists can be implemented in ML/Haskell as functional data structures, but they don't have O(1) append and turn-into-a-regular-list operations; my Levy# difference lists, represented as values of type list -o list, can perform all these operations in constant time with local pointer manipulation. The cost is that operations on linear functions are implemented by destructive pointer mutation - I should really have an affine type system to ensure that values of type list -o list are used at most once.
- In Part 2, I observed that the perfectly natural, λProlog/Twelf-inspired operation of matching against these linear functions greatly increased their expressive power. By adding an extra bit of information to the runtime representation of data (an answer to the the question "where is the hole, if there is a hole?"), the matching operation could be done in constant time (well, time linear in the number of cases). A simple subordination analysis meant that checking for exhaustiveness and redundancy in case analysis was possible as well.
The essence of zippers
A zipper is a functional data structure that allows you to poke around on the inside of a datatype without having to constantly descend all the way int the datatype. Illustrations of zippers generally look something like this:1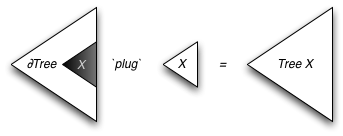
The zipper data structure consists of two parts: one of them is a "path" or "one-hole-context", which, owing to Conor's influence [1], I will call a derivative, and the other is a subterm. We maintain the invariant that as we move into the derivative ("up") or into the subterm ("down") with constant-time operations, the combination of the derivative and the subterm remains the original term that we are editing. A Levy# implementation of derivative-based zippers as presented in Huet's original paper on zippers [2] can be found in thezipper.levy.
To understand linear function-based zippers, we see that a linear term a -o b is kind of obviously a b value with one a value missing, so if we pair a value a -o b with a value of type a, we would hope to be able to use the pair as a zipper over b values. The one thing that we can't do with the linear functions we've discussed so far, however, is look "up" in the tree.
A list is a good simple example here, since the two parts of a linear function-based zipper over a list are a difference list (the beginning of the list) and a list (the end of the list). Looking "up" involves asking what the last item in the list -o list is (if there is at least one item). Since a value of type list -o list has the structure [hole: list] Cons n1 (Cons n2 ... (Cons nk-1 (Cons nk hole))...), it's reasonable to match this term against the pattern [hole: list] outside (Cons i hole) to learn that outside is [hole: list] Cons n1 (Cons n2 ... (Cons nk-1 hole)...) and that i is nk. The key is that, in the pattern, the linear variable hole appears as the immediate subterm to the constructor Cons, so that we're really only asking a question about what the closest constructor to the hole is.
This kind of interior pattern matching is quite different from existing efforts to understand "pattern fragments" of linear lambda cacluli (that I know of), but it's perfectly sensible. As I'll show in the rest of this post, it's also easy enough to modify the implementation to deal with interior pattern matching efficiently, easy enough to do exhaustiveness checking, and easy enough to actually use for programming. For the last part, I'll use an example from Michael Adams; you can also see the linear pattern matching version of Huet's original example on Github: (linzipper.levy).
Implementation
The only trick to implementing zippers that allow interior pattern matching is to turn our linked list structure into a doubly linked list: the final data structure basically is a double-ended queue implemented by a doubly-linked list.First: we make our "tail pointer," which previously pointed into the last structure where the hole was, a pointer to the beginning of the last allocated cell, the one that immediately surrounds the hole. This lets us perform the pattern match, because we can see what the immediate context of the hole is just by following the tail pointer. (It also requires that we create a different representation of linear functions that are the identity, but that's the kind of boring observation that you can get by implementing a doubly-linked list in C.)
After we have identified the immediate context of the hole, we also need a parent pointer to identify the smaller "front" of the linear function. The in-memory representation of [hole: list] Cons 9 (Cons 3 (Cons 7 hole)), for example, will look something like this:

Just like the "where is the hole" information, this parent pointer gets to be completely ignored by the runtime if it hangs around after the linear function is turned into a non-holey value.
Exhaustiveness checking
Providing non-exhaustive match warnings for case analysis on the inside of a linear function is a bit tricker than providing non-exhaustive match warnings for case analysis on the outside of a linear function, but it's only just a bit trickier. First, observe that the subordination relation I talked about in the previous installment is the transitive closure of an immediate subordination relation that declares what types of values can be immediate subterms to constructors of other types. For instance, when we declare the type of the constructor Cons to be int -o list -o list, Levy# learns that int and list are both immediately subordinate to list.Levy# was already tracking both the immediate subordination relation and the full subordination relation; we can change the output of the "print subordination" command to reflect this reality:
Levy. Press Ctrl-D to exit.
Levy> data Z: even | EO: even -o odd | OE: odd -o even ;;
data Z: even
| EO: even -o odd
| OE: odd -o even
Levy> $subord ;;
Subordination for current datatypes:
even <| even
even <| odd (immediate)
odd <| even (immediate)
odd <| oddNow, the way we enumerate the possible cases for an interior pattern match against a linear value of type holeTy -o valueTy is the following:- Enumerate all of the types ctxTy that holeTy is immediately subordinate to. These are all the types with constructors that might immediately surround the hole (which, of course, has type holeTy).
- Filter out all the types ctxTy above that aren't subordinate to, or the same as, the value type valueTy.
- For every constructor of the remaining types ctxTy, list the positions where a value of type holeTy may appear as an immediate subterm.
Case Study: No, Really, Scrap Your Zippers
When I said that this idea had been kicking around in my head since shortly after WGP 2010, I meant specifically since the part of WGP 2010 when Michael Adams presented the paper "Scrap Your Zippers". One of the arguments behind the Scrap Your Zippers approach is that Huet's zippers involve a lot of boilerplate and don't work very well for heterogenerous datatypes.Small examples tend to minimize the annoyingness of boilerplate by virtue of their smallness, but the example Adams gave about heterogeneous zippers works (almost) beautifully in our setting. First, we describe the datatype of departments, which are pairs of an employee record (the boss) and a list of employees (subordinates):
data E: name -o int -o employee ;;
data Nil: list
| Cons: employee -o list -o list ;;
data D: employee -o list -o dept ;;
val agamemnon = E Agamemnon 5000 ;;
val menelaus = E Menelaus 3000 ;;
val achilles = E Achilles 2000 ;;
val odysseus = E Odysseus 2000 ;;
val dept = D agamemnon
(Cons menelaus
(Cons achilles
(Cons odysseus Nil))) ;;Our goal is to zipper our way in to the department value dept and rename "Agamemnon" "King Agamemnon."
The reason this is only almost beautiful is that Levy# doesn't have a generic pair type, and the type of zippers over a heterogeneous datatype like dept is a pair of a linear representational function T -o dept and a value T for some type T. So, we need to come up with specific instances of this as datatypes, the way we might in Twelf:
data PD: (dept -o dept) -o dept -o paird ;;
data PE: (employee -o dept) -o employee -o paire ;;
data PN: (name -o dept) -o name -o pairn ;;
Given these pair types, we are able to descend into the structure without any difficulty: # Create the zipper pair
val loc = PD ([hole: dept] hole) dept ;;
# Move down and to the left
comp loc =
let (PD path dept) be loc in
let (D boss subord) be dept in
return PE
([hole: employee] path (D hole subord))
boss ;;
# Move down and to the left
comp loc =
let (PE path employee) be loc in
let (E name salary) be employee in
return PN
([hole: name] path (E hole salary))
name ;;At this point, we could just do the replacement in constant time by linear application: comp revision =
let (PN path name) be loc in
return path KingAgamemnon ;;For comparison, the Scrap Your Zippers framework implements this with the function fromZipper.
However, everything above could have been done in the previous installment. Our new kind of pattern matching reveals its power when we try to walk "up" in the data structure, so we'll do that instead. The first step takes us back to an employee -o dept zipper, and is where we give Agamemnon his kingly designation:
comp loc =
let (PN path name) be loc in
let ([hole: name] path (E hole salary)) be path in
return PE path (E KingAgamemnon salary) ;;The first step was easy: the only place a name hole can appear in an dept datatype is inside of an employee. An employee, however, can appear in a value of type dept in one of two paces: either as the boss or as one of the members of the list of subordinates. Therefore, if we want to avoid nonexhaustive match warnings, we have to give an extra case:2 comp revision =
let (PE path employee) be loc in
match path with
| [hole: employee] D hole subord ->
return D employee subord
| [hole: employee] path (Cons hole other_subord) ->
return dept ;; # Error?Note that, in the first match above, the case was [hole: employee] D hole subord, not [hole: employee] path (D hole subord). As in the previous installment, I used the subordination relation to conclude that there were no values of type dept -o dept other than the identity; therefore, it's okay to allow the simpler pattern that assumes path is the identity.
The code for this example is in scrap.levy.
Conclusion
Proposals for radically new language features should be treated with some care; do they really add enough expressiveness to the language? I hope that this series has at least suggested the possibility that linear function types might be desirable as a core language feature in a functional language. Linear representational functions expand the class of safe, pure algorithms to capture algorithms that could previously only be done in an impure way, and they give a completely principled (and cast-free) way of scrapping your zipper boilerplate.And perhaps the most important feature of this proposal is one I haven't touched so far, which is the added simplicity of reasoning about programs, both informally and formally. As for the "informally," if you've ever been flummoxed by the process of making sure that your heavily tail-recursive program has an even number of List.rev errors, or if you have avoided making functions tail-recursive for precisely this reason, I think linear representational functions could be a huge help. One thing I'd like to do if I have time is to work through type inference in context with linear representational functions; I imagine many things would be much clearer. In particular, I suspect there wouldn't be any need for both Cons and Snoc lists or the "fish" operator.
The formal reasoning aspect can be glimpsed by looking at the previous case study: proving that the tail-recursive functions lin_of_zip and zip_of_lin are inverses has the structure of a double-reverse theorem (proving that List.rev (List.rev xs) = xs). Maybe it's just me being dense, but I have trouble with double-reverse theorems. On the other hand, if we needed to prove that the structurally-inductive and not tail-recursive functions lin_of_zip' and zip_of_lin' (which we can now implement, of course) are inverses, that's just a straightforward induction and call to the induction hypothesis. And making dumb theorems easier to prove is, in my experience at least half the battle of using theorem provers.
Expressiveness and efficiency, reloaded
The claim that linear representational functions can completely subsume zippers is undermined somewhat by the emphasis I have put on making matching and other operations O(1). Just to be clear: I can entirely implement linear representational functions using functional data structures (in fact, by using derivatives!) if I'm not concerned with performance. There's even a potential happy medium: rather than invalidating a zipper, I think it would be possible to merely mark a zipper as "in use," so that the second time you use a zipper it gets silently copied. This means that if you think about affine usage, you get constant-time guarantees, but if you just want to use more-awesome zippers, you can program as if it was a persistent data structure. This "persistent always, efficient if you use it right" notion of persistant data structures has precedent, it's how persistent union-find works.1 That particular image is a CC-SA licensed contribution by Heinrich Apfelmus on the Haskell Wikibook on zippers. Thanks, Heinrich!
2 If we had a polymorphic option type we could just return Some or None, of course. Meh.
[1] Conor McBride, "The Derivative of a Regular Type is its Type of One-Hole Contexts," comically unpublished.
[2] Gúrard Huet, "Function Pearl: The Zipper," JFP 1997.
[3] Michael D. Adams "Scrap Your Zippers," WGP 2010.


This was a fun series! I wonder if you've seen the paper "A Functional Representation of Data Structures with a Hole" by Minamide, which is related (though less elegantly presented):
ReplyDeletehttp://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.8.5594
I spent a few weeks with Claudio Russo this summer thinking about some of this stuff, and one thing I'd suggest looking at is Deutsch-Schorr-Waite algorithms coded via this representation of zippers.
These ideas also relate to the very nice paper by Sobel and Friedman, "Recycling continuations".
I hadn't heard about any of these things, thanks for sharing these! I've posted a follow-up about Minamide's paper: http://requestforlogic.blogspot.com/2011/08/holey-data-postscript-hole-abstraction.html
ReplyDelete